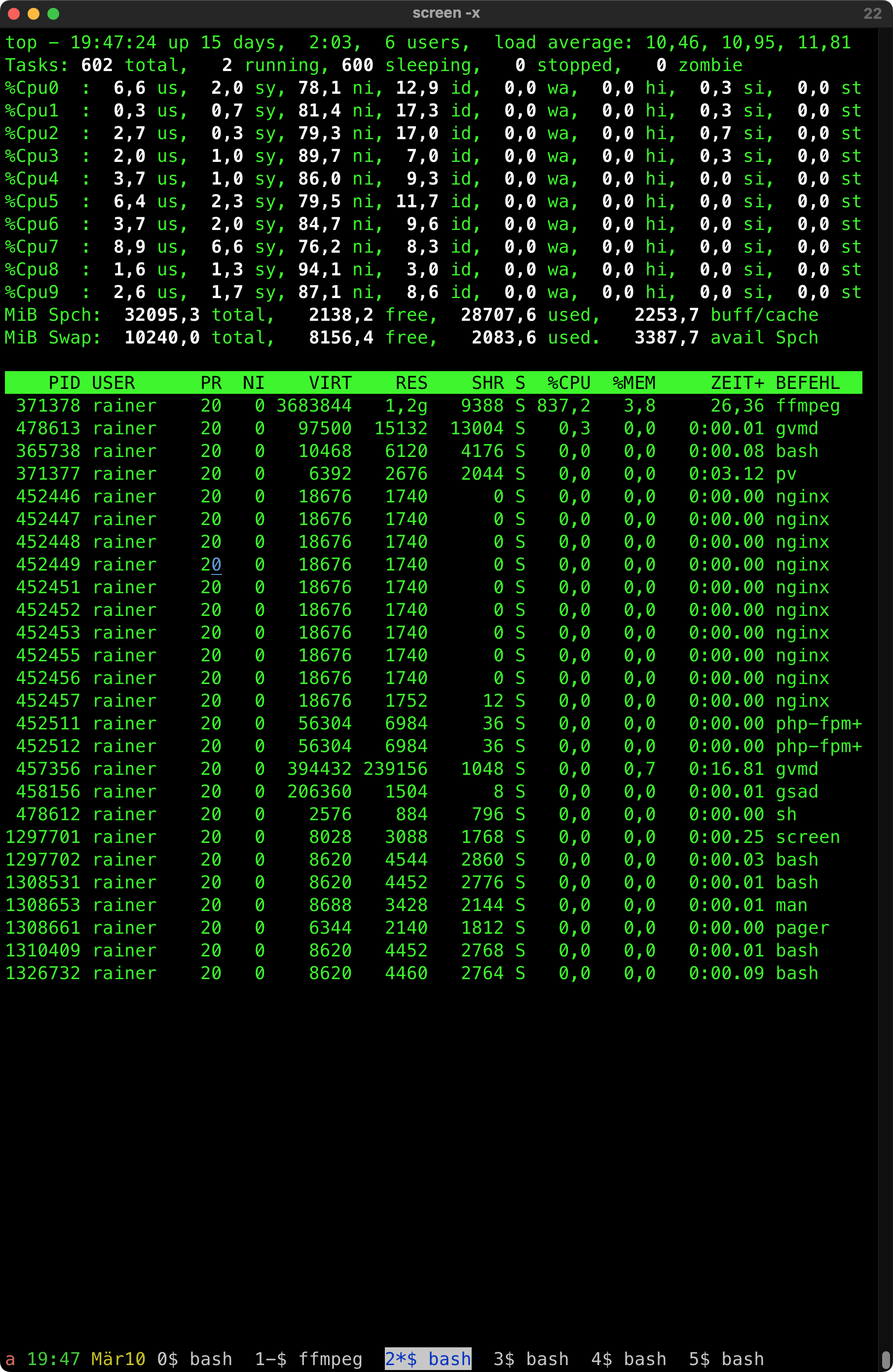
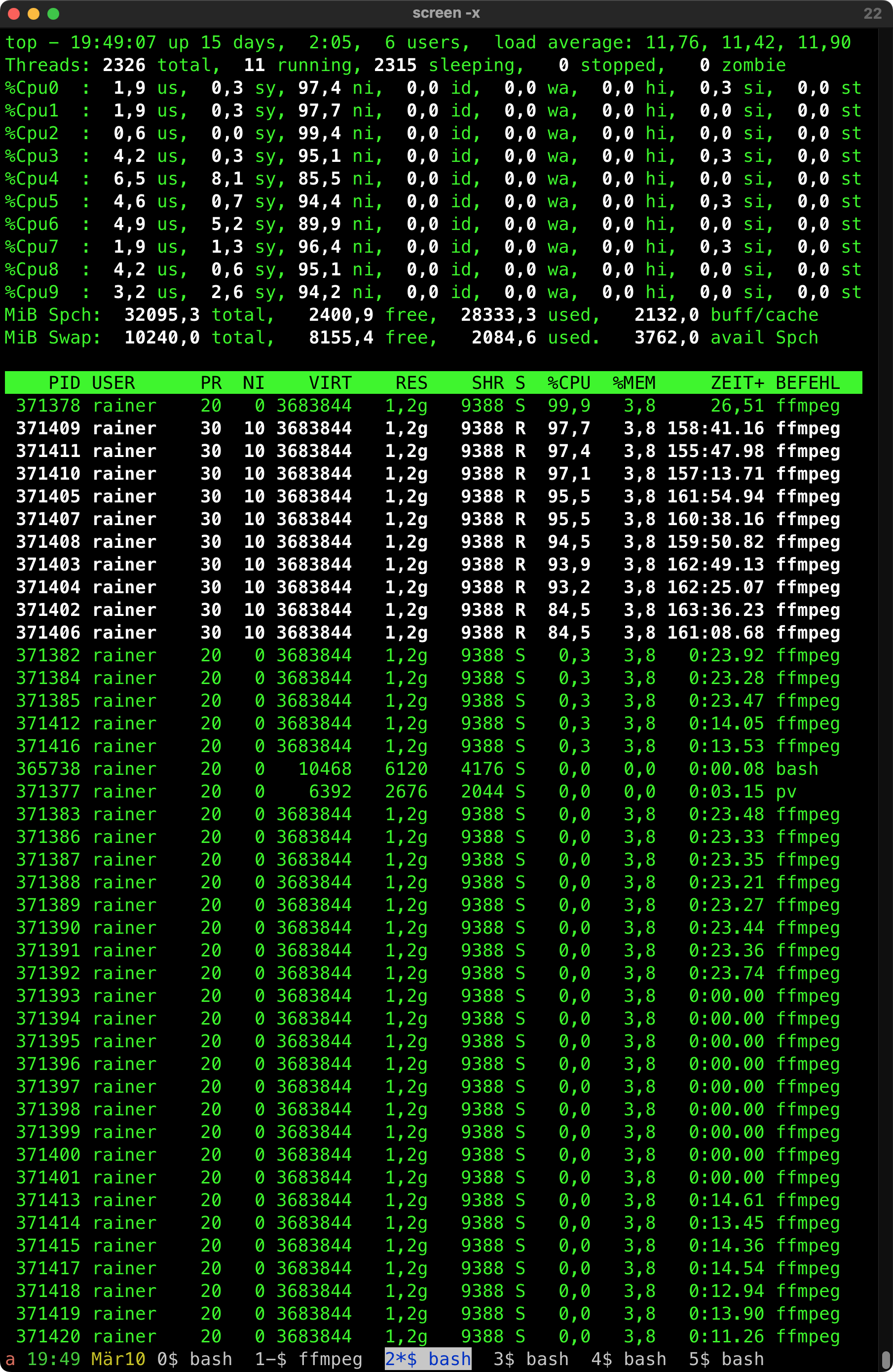
Unser Zweit-Kühlschrank hat eine Macke, und zwar hört er ab und an, die letzen 3 Wochen vielleicht 3 mal, auf zu kühlen.
Als Feierabendbiertrinker bemerke ich das zwar, aber Monitoring by Biertrinktemperatur ist fehleranfällig, zumal man eigentlich 24/7 trinken müßte.
Der Kühlschrank erholt sich wieder, wenn man ihn einen Tag (möglicherweise auch kürzer, ich habs nicht getestet) vom Strom nimmt.
Irgendwann werden wir ihn ersetzen müssen, aber nicht demnächst.
Um also die Leber zu entlasten, muß ein Monitoring her, natürlich mit Alarmierung, Eskalationen und dem ganzen Zinnober.
#Zabbix!
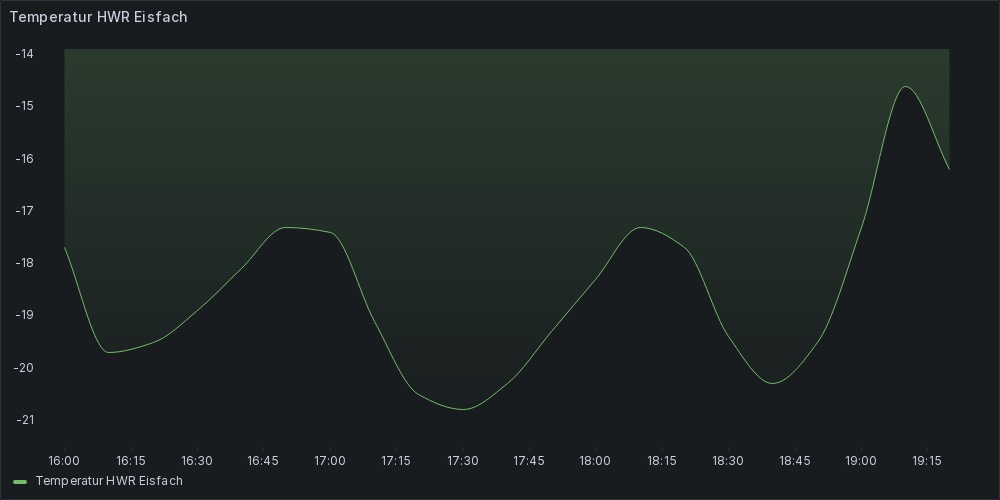
Heute kam das Thermometer, ich habe schon lange eine Wetterstation, an die ich mehrere Sensoren für Temperatur und Luftfeuchtigkeit anknüppern kann.
Gemacht, getan, jetzt nur noch die Temperatur auslesen.
Das kann zwar lokal bleiben, dann habe ich aber nur eine Anbindung an Home Assistant. Vermutlich könnte ich Zabbix auch an Home Assistant anflanschen, aber einfacher gehts über die API im Internet:
#!/bin/bash /usr/bin/curl -s \ 'https://api.ecowitt.net/api/v3/device/real_time?application_key=[…]&api_key=[…]&mac=[…]&call_back=all&temp_unitid=1' | \ /usr/bin/jq -r .data.temp_and_humidity_ch8.temperature.value
Funktioniert:
❯ ./wetterstation.hwr.eisfach-temperatur.sh -14.7
Jetzt nur noch ein Item basteln in Zabbix:
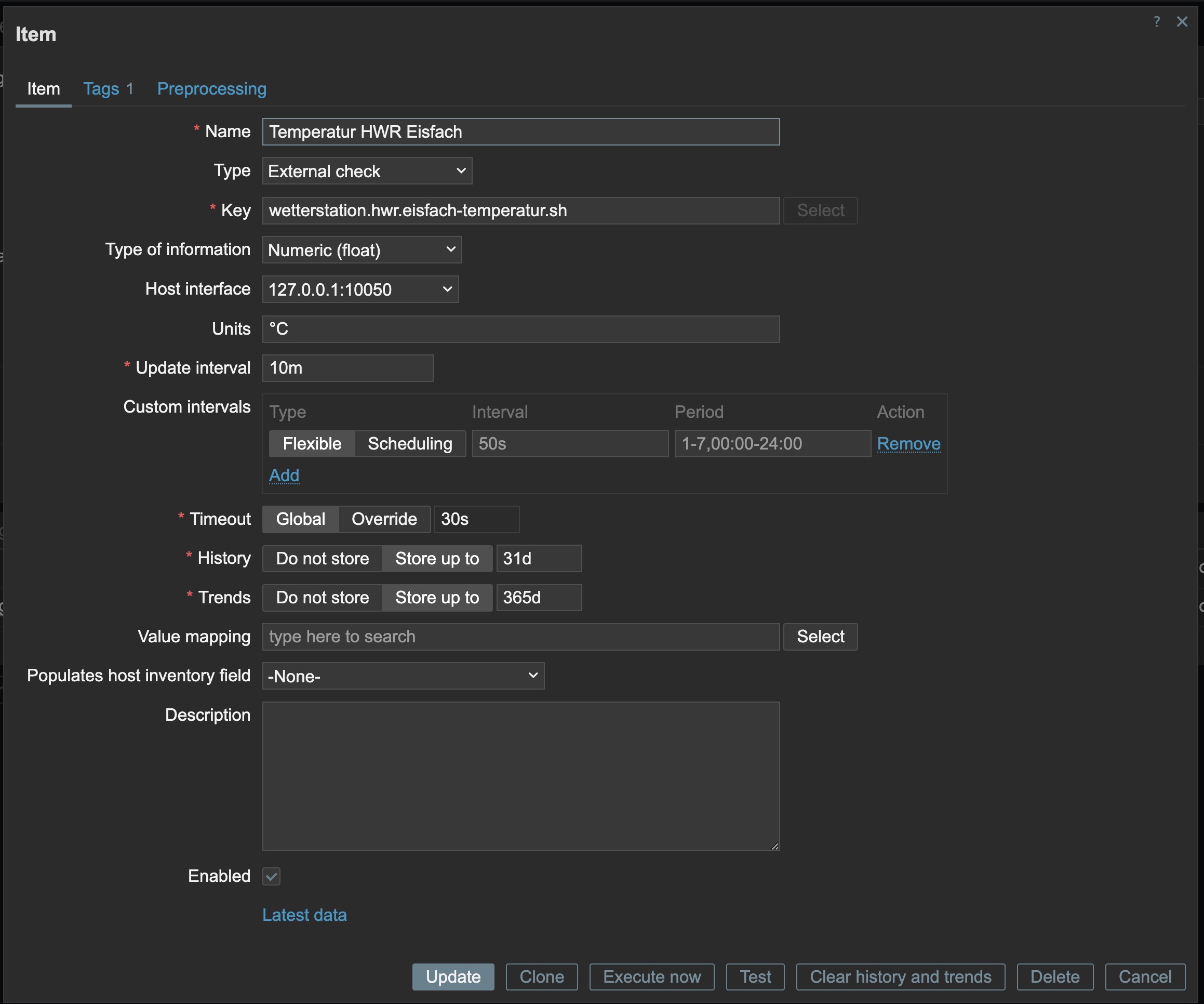
Und den entsprechenden Trigger, der bei einer Temperatur gleich oder über ‑15°C auslösen soll:

Einbiegen auf die Zielgerade, wir brauchen ja noch die Benachrichtigung:
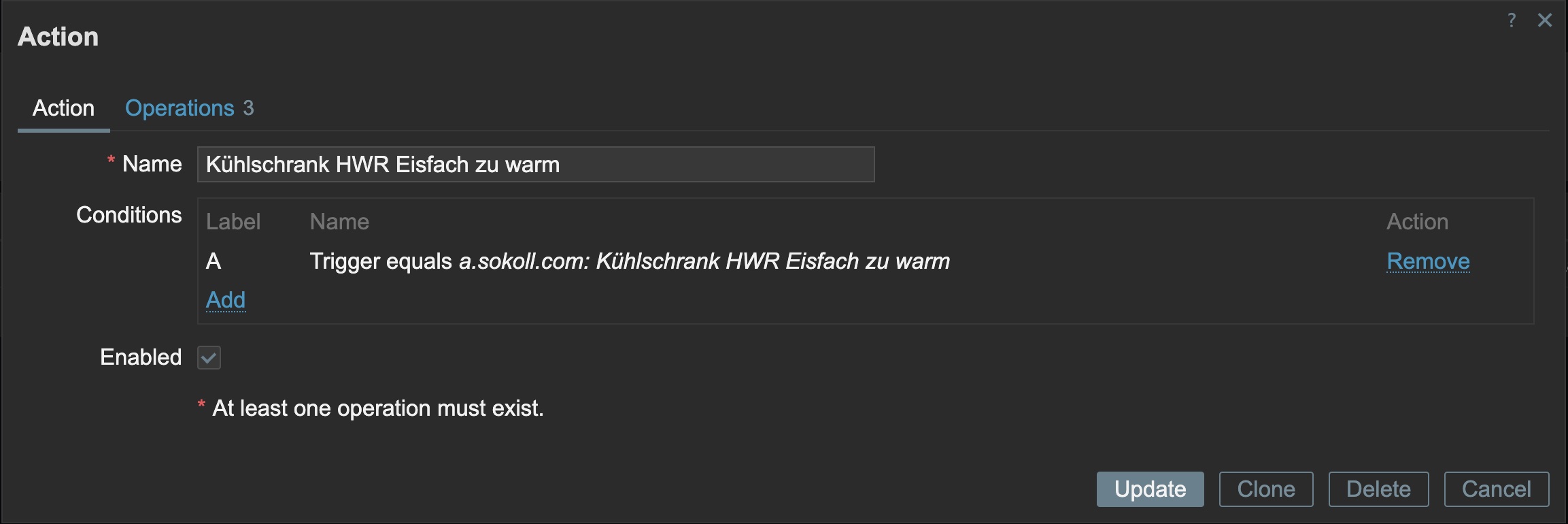
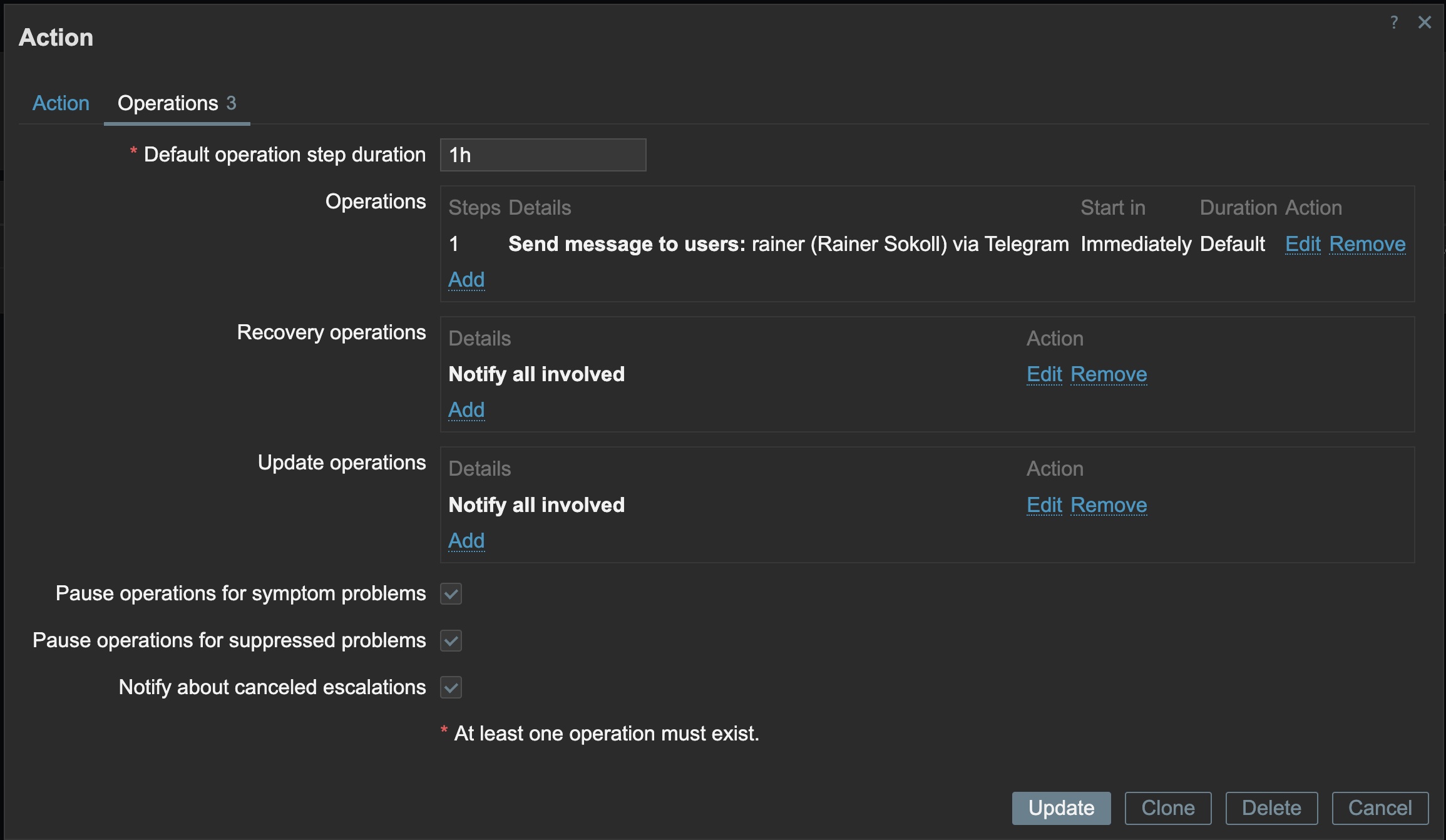
Und nun nur noch, wer auf welchem Wege alarmiert werden soll: ich, via Telegram.
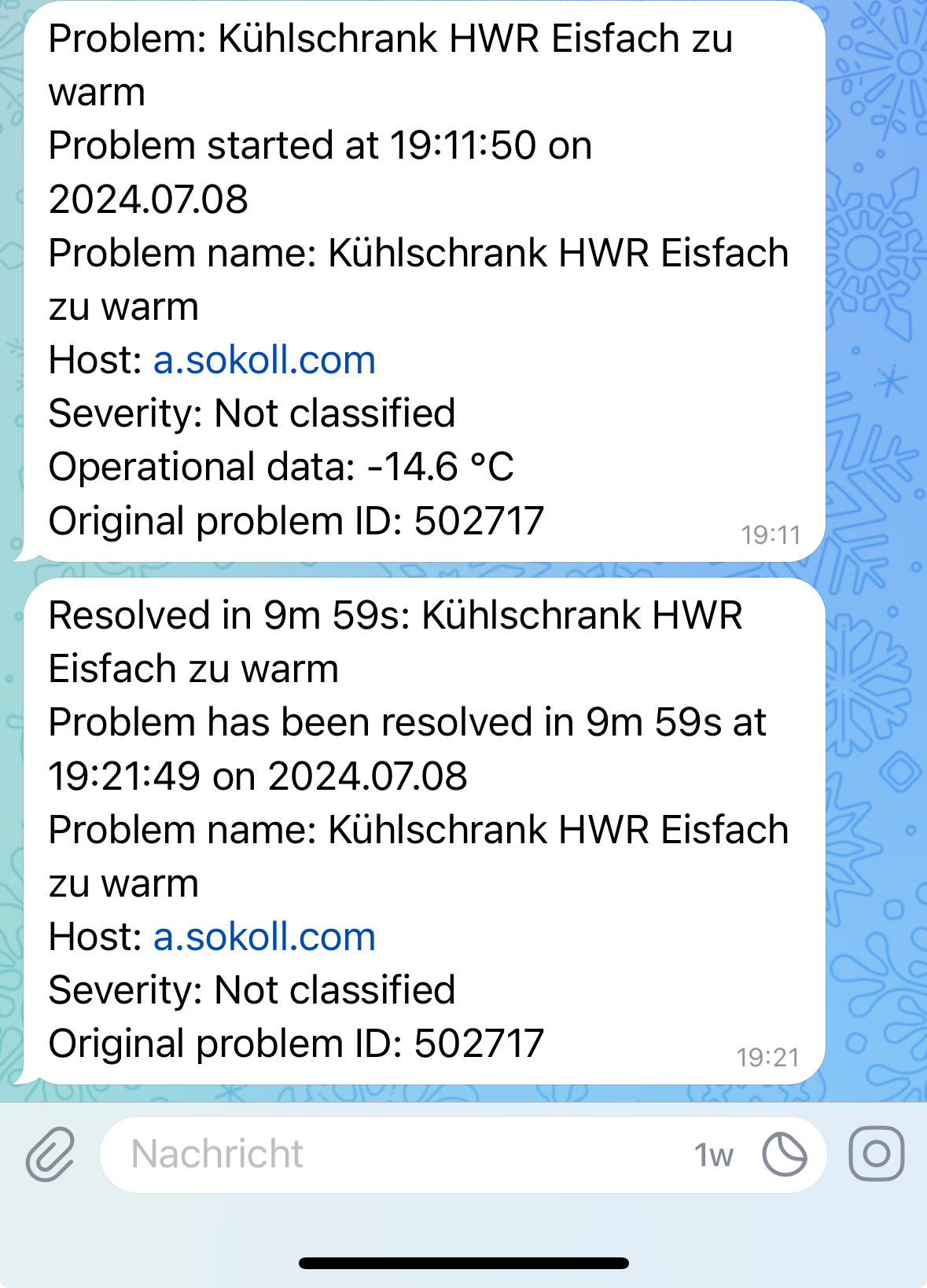
Funzt!
Und wenn wir schon dabei sind: #Grafana!